Georges Dubus has created pyramid_persona, a nice library to integrate
Mozilla Persona authentication into Pyramid projects.
He also wrote a tutorial blog post explaining the basics of how to use
the library.
In principle it should be easy to go from what Georges has written to getting
Persona-based authentication fully integrated with group or object level
authorization in a Pyramid project,
but it took some head scratching for me to do that.
What better reason to blog about what I came up with and build on Georges'
excellent work...
By the way,
pyramid_persona is also a really nice example of advanced configuration
tactics in Pyramid that show off the framework's plug-in friendliness.
Before diving is, I should also mention that Michael Merickel's
authentication and authorization tutorial is an indispensable reference.
The Goal: The example I'm going to use is a very simple group-level authorization one.
We'll create a site with a public side that anyone can interact with,
and a private side that only allows access by users who have authenticated
via Persona,
and are known to the app as members of the admin group.
We'll use the alchemy scaffold,
so the app will have URL mapping via URL dispatch and persistence via
SQLAlchemy.
So, let's get started.
Create a virtualenv,
install Pyramid,
and create an alchemy scaffold app:
(ppga)$ pcreate -s alchemy pyramid_persona_group_auth_demo
Add pyramid_persona to the requires list in setup.py,
and add some settings to development.ini:
persona.secret = some secret string
persona.audiences = http://localhost:6543
persona.siteName = Pyramid Persona Group Auth Demo
mako.directories = pyramid_persona_group_auth_demo:templates
The persona settings are described in the Configuration section of the
pyramid_persona README.
The mako.directories setting is needed because we're going to use Mako for
our login and admin page templates.
Next up, we add an Administrator class to our models.py file:
class Administrator(Base):
__tablename__ = 'admins'
id = Column(Integer, primary_key=True)
persona_email = Column(Text, index=True, unique=True)
def __init__(self, persona_email):
self.persona_email = persona_email
We also need to bootstrap our Persona email address into the database
so that we can sign-in to our app when we first start it up.
To do that, import Administrator into scripts/initializedb.py
and add a couple of lines to the end of the main function in that file:
from ..models import Administrator
...
with transaction.manager:
model = MyModel(name='one', value=1)
DBSession.add(model)
admin = Administrator(persona_email='me@example.com')
DBSession.add(admin)
Obviously, you'll want to use an email address that you have registered with
Persona in place of me@example.com.
Now it's time to create some templates and views for the admin site of our
site.
These pages are almost verbatim from Georges' blog post or the
pyramid_persona README - he really has done most of the heavy lifting!
We start with a stub for the admin home page in templates/admin_home.mako:
<!DOCTYPE html>
<html>
<head>
<script type="text/javascript"
src="//ajax.googleapis.com/ajax/libs/jquery/1.8.2/jquery.min.js">
</script>
<script src="https://login.persona.org/include.js"></script>
<script >${request.persona_js}</script>
</head>
<body>
<h1>Pyramid Persona Group Auth Demo Admin</h1>
Welcome to the admin side, ${userid}
${request.persona_button}
</body>
</html>
All we've done here is hooked into Persona, and set up a welcome message and
a sign-out button in lieu of any real admin interface content and funtionality.
The request.person_js and request.persona_button attributes are
available thanks to config.set_request_property() calls in
pyramid_persona.__init__.py.
Recall that I mentioned what a nice example
of advanced Pyramid configuration pyramid_persona is -
it's well worth reading Georges' code to learn how he has made things so
easy for the rest of us.
We'll also create a very similar looking template for our sign-in page in
templates/admin_signin.mako:
<!DOCTYPE html>
<html>
<head>
<script type="text/javascript"
src="//ajax.googleapis.com/ajax/libs/jquery/1.8.2/jquery.min.js">
</script>
<script src="https://login.persona.org/include.js"></script>
<script >${request.persona_js}</script>
</head>
<body>
<h1>Pyramid Persona Group Auth Demo Admin</h1>
${request.persona_button}
</body>
</html>
There are obviously some opportunities to use template inheritance here,
to say nothing of the total absence of styling in those templates.
Moving along to the views that render those templates, we create
admin_views.py containing:
from pyramid.renderers import render
from pyramid.response import Response
from pyramid.security import authenticated_userid
from pyramid.view import (
forbidden_view_config,
view_config,
)
@forbidden_view_config()
def admin_signin(request):
body = render('admin_signin.mako', {}, request=request)
return Response(body, status='403 Forbidden')
@view_config(
route_name='admin.home',
renderer='admin_home.mako',
permission='admin')
def admin_home(request):
userid = authenticated_userid(request)
return {'userid': userid}
The admin_signin function renders our admin_signin.mako template
and packages it up as a 403 Forbidden response.
That function is decorated with @forbidden_view_config() so that it will
replace the default forbidden view that pyramid_persona supplies.
That's how we get our sign-in page to appear when an unauthenticated user
hits the admin URL.
The admin_home function renders our admin home page stub.
The important thing to note here is the permission='admin' argument in
the @view_config decorator.
Finally, we add our security policy to
pyramid_persona_group_auth_demo/__init__.py and add our admin home page
view to the route map.
We need some new imports:
from pyramid.authentication import AuthTktAuthenticationPolicy
from pyramid.security import ALL_PERMISSIONS
from pyramid.security import Allow
from sqlalchemy.orm.exc import NoResultFound
from .models import Administrator
Then we add a dirt simple resource tree to provide the access control list
that implements our security policy; i.e. any user in the admin group
has full access to admin resources:
class Root(object):
"""Simplest possible resource tree to map groups to permissions.
"""
__acl__ = [
(Allow, 'g:admin', ALL_PERMISSIONS),
]
def __init__(self, request):
self.request = request
We also need a groupfinder function to provide to the authentication
policy constructor so that it can identify whether or not an authenticated
user is in the admin group:
def groupfinder(userid, request):
query = DBSession.query(Administrator).\
filter(Administrator.persona_email == userid)
try:
query.one()
return ['g:admin']
except NoResultFound:
return None
Now let's hook everything together via the configuration in the
main function.
We add our resource tree to the Configurator constructor call:
config = Configurator(settings=settings, root_factory=Root)
as well as including the pyramid_persona configuration,
and overriding its authentication policy setting with our own that hooks in
the groupfinder function:
config.include('pyramid_persona')
authn_policy = AuthTktAuthenticationPolicy(
settings['persona.secret'],
callback=groupfinder)
config.set_authentication_policy(authn_policy)
Last but not least, we add a route to map /admin to our admin home page:
config.add_route('admin.home', '/admin')
It's time to test!
Install our app to get all of the dependencies installed,
initialize the database with the handy
initialize_pyramid_persona_group_auth_demo_db command that Pyramid
creates for us during installation of an alchemy scaffold app,
and start the server:
(ppga)$ python setup.py develop
(ppga)$ # lots of output
(ppga)$ initialize_pyramid_persona_group_auth_demo_db development.ini
(ppga)$ pserve --reload development.ini
Browsing to http://localhost:6543 should show you the default Pyramid
app page - that's the public side of our site.
Going to http://localhost:6543/admin should show you the admin
sign-in page:
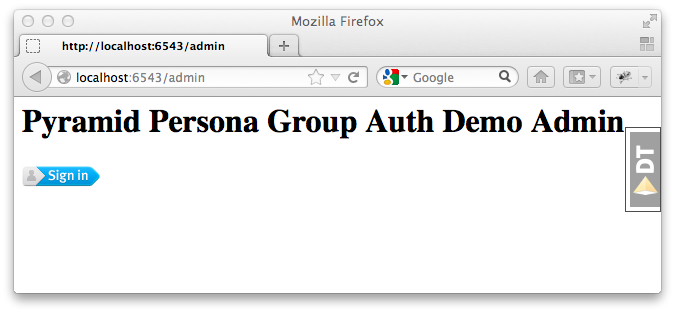
and, if you inspect the requests and responses with your browser's web dev
tools, you'll see that we got the expected 403 Forbidden response status.
Clicking the sign-in button pops the login.persona.org site in a new
window with our site name and audience domain displayed:
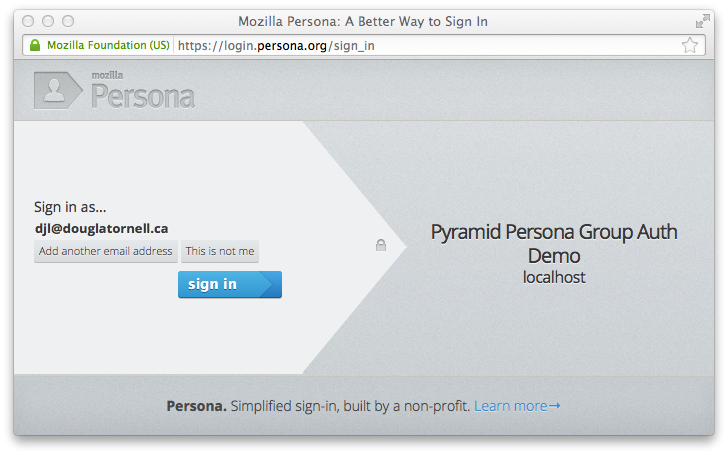
And, upon successfully signing in at Persona, we are redirected to the admin
home page of our site:
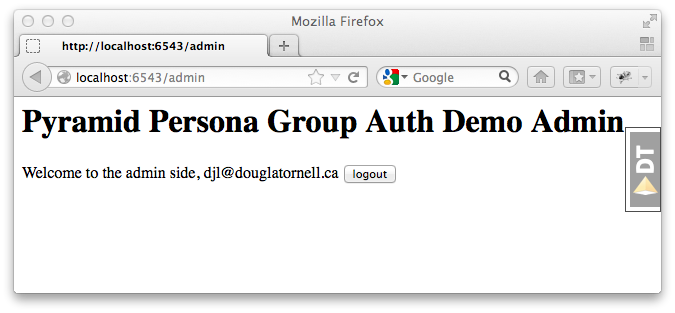
And that's all there is to it!
Extending the site security to a more fine-grained group-level hierachy,
or to object-level security should be relatively easy with the guidance
in Michael Merickel's authentication and authorization tutorial.
The source code for the demo I've created here is available on Bitbucket at
https://bitbucket.org/douglatornell/pyramid_persona_group_auth_demo
Thanks again to Georges Dubus for making this easy with the pyramid_persona
library, and to Mozilla for creating Persona.
Updated 2012-11-02
- Fixed typo in import statement for Administrator model.
Thanks ppaez!
- Added index on persona_email column of Administrator model.
Thanks Georges Dubus!